SharePoint offers a robust out-of-the-box approval workflow for its lists, enabling efficient and controlled document and task management. This blog post will guide you through the process of setting up and utilizing this powerful feature.
Setting Up List Approvals:
1. Create a New List:
a. Navigate to your SharePoint site's "Site Contents" page.
b. Click "Add a list" and select "Blank List".
.png)
.png)
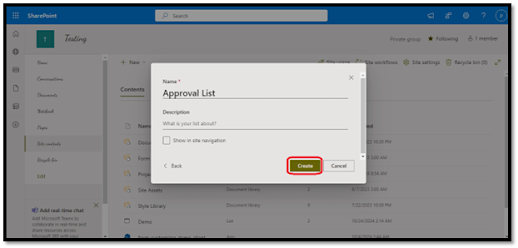
c. Give your list a suitable name (e.g. "Approval List").
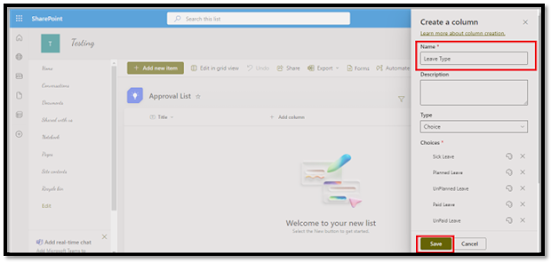
d. Create necessary columns (e.g. "Leave Type", "Description", "Start Date", "End Date").
.png)
.png)
2. Enable Approvals
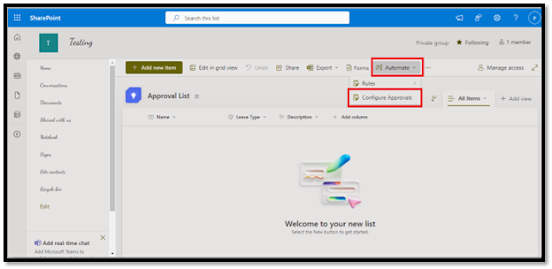
a. In the list ribbon, click "Automate" and then "Configure Approvals".
.png)
.png)
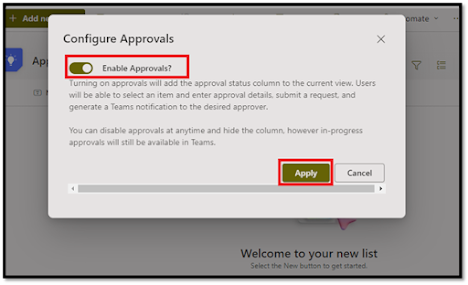
b. Toggle the "Enable Approvals" switch on and click on "Apply".
.png)
.png)
c. This action automatically adds an Approval Status column to your list, tracking the stage of each approval.
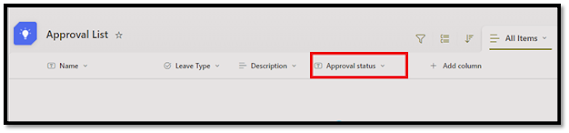.png)
.png)
Creating a New Item to Test the Approval Request:
1. Create a New Item:
a. Click on "New" to add a new item to your list.
b. Fill in the required details (e.g. leave type, description).
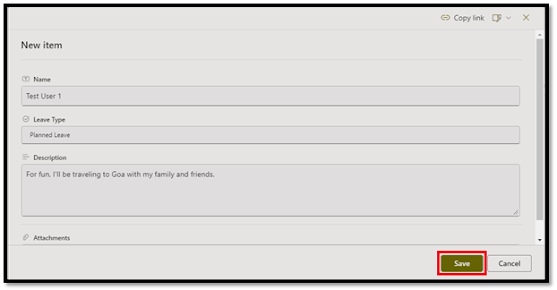.png)
.png)
c. The "Approval Status" will automatically be set to "Not Submitted".
.png)
.png)
2. Submit for Approval Request:
a. Click on the "Not Submitted" Status.
b. In the pop-up, select the Approver's Name(s) using the People picker and Add any additional comments or details, then click "Submit" to send the item for approval.
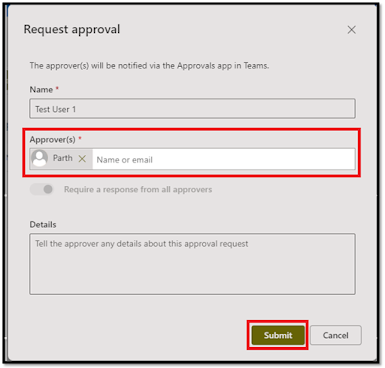.png)
.png)
3. Monitor Approval Status:
a. After a few minutes, the Approval Status will be changed from Not Submitted to Requested.
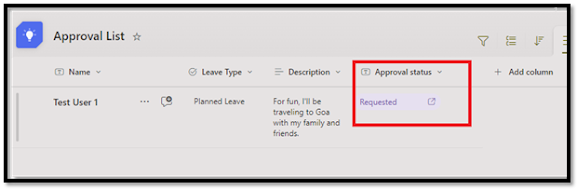.png)
.png)
b. You can check the status of the approval at any time from the list.
4. Enable Approval Notifications in Microsoft Teams:
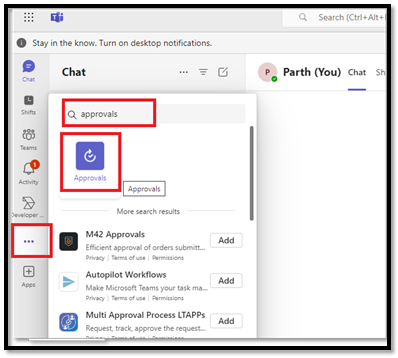
a. To receive approval notifications in Teams, add the Approvals app.
b. Open Teams, click on the three dots(...) search for Approvals, and click Add.
.png)
.png)
c. This integration enables you to receive real-time notification for approval actions in Teams.
5. Understanding Approval Actions:
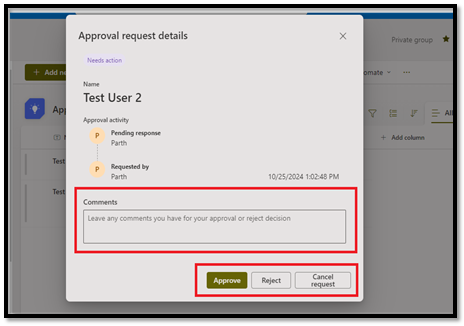
a. When an item is submitted, the status changes to Requested. At this stage, approvers can view the item's approval history and choose from several actions:
b. Approval using SharePoint:
.png)
.png)
c. Approval Process using Teams:
.png)
.png)
i. Approve: Click he "Approve" button to approve the request.
ii. Rejected: Declines the request, updating the Approval Status to Rejected.
iii. Cancel Request: Withdraws the request, resetting the Approval Status to No Submitted.
iv. Follow Up: Click the "Follow Up" button to send a reminder or query to the requester.
v. Reassign: Transfer the approval responsibility to another person, ensuring approvals are handled even if the original approver is unavailable.
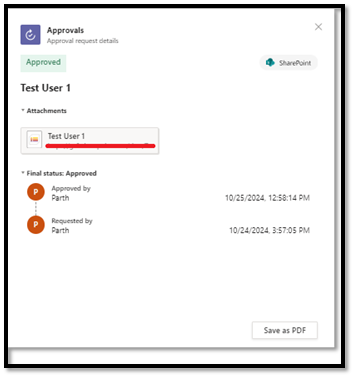
6. Checking Approval History:
a. Each item in the list retains a history of actions, which includes who approved, rejected, or reassigned the item.
.png)
.png)
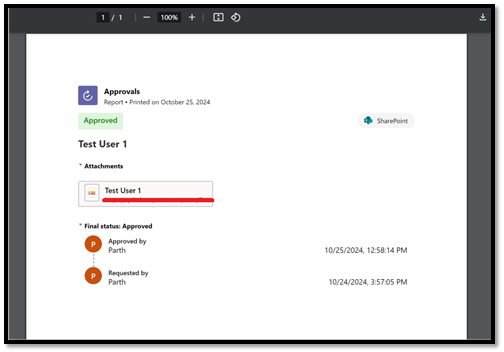
7. Save Approval History as PDF:
a. Once a request is completed, you can save the approval record as a PDF for documentation purposes.
.png)
.png)
8. Additional Submissions:
a. You can submit new requests or resubmit previously canceled requests, creating a flexible approval process where items can be reassigned or resubmitted as needed.
Understanding the Approval Process:
- Initial Status: "Not Submitted"
- Pending Approval: "Requested"
- Approved: "Approved"
- Rejected: "Rejected"
- Canceled: "Not Submitted"
Pros and Cons of SharePoint List Approvals:
Pros:
- Simplified Workflow: Simplifies the approval procedure.
- Easy Setup: No complex setup or external tools are required; the entire process is available within SharePoint's Automate menu.
- Enhanced Control: Centralized management of approvals.
- Improved Visibility and Tracking: Real-time tracking of approval status. The Approval Status column and history racking make it easy to monitor the status of each request.
- Efficient Collaboration: Facilities timely decision-making.
- Enhanced Security: Ensures authorized access and control.
- Reassign and Follow-up Options: These features increase flexibility, ensuring requests are not left unattended.
Cons:
- Limited Customization: Basic approval workflow may not suit complex scenarios.
- Dependency on SharePoint: Requires SharePoint access for approval management.
- Approval Logic: There's limited support for custom approval logic, such as multi-level or conditional approvals.
- Notification Delays: There may be delays in notifications for approval actions in Teams, impacting immediate responses.
- Steeper Learning Curve: Initial setup and configuration can be time-consuming.
Additional Tips:
- Clear and Concise Descriptions: Provide detailed explanations for approval requests.
- Timely Responses: Promptly review and respond to approval requests.
- Effective Communication: Use clear and concise language in comments and notifications.
- Leverage Teams Integration: Utilize Teams for real-time collaboration and notifications.
- Customize Approval Workflows: For more complex scenarios, consider using Power Automate to create custom workflows.
Conclusion
SharePoint's out-of-the-box list approval process is a practical solution for straightforward approval needs, particularly for organizations already using SharePoint and Microsoft Teams. While it lacks the customization of more advanced workflow solutions, it is efficient and well-integrated within Microsoft 365, providing essential functionality to streamline approvals.
By following these steps and leveraging the pros of SharePoint List Approvals, you can significantly improve your organization's efficiency and productivity.
If you have any questions you can reach out our SharePoint Consulting team here.

























