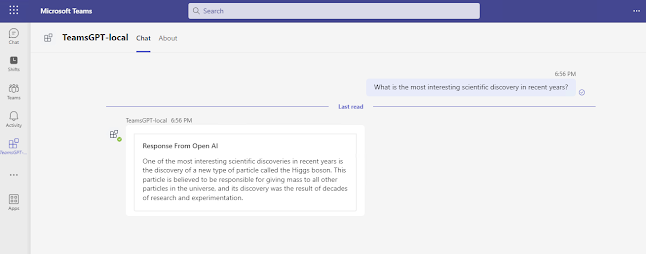
Introduction:
In the ever-evolving world of artificial intelligence, Azure AI Language Service stands out as a formidable tool that promises to revolutionize the way we interact with and analyze textual content.
This article will dive you into the depths of Azure AI Language Service, offering a comprehensive overview and insight into its capabilities. Also we will witness the magic of document summarization in a small yet powerful React application.
This interactive experience will showcase how seamlessly Azure AI Language Service integrates with modern web technologies, providing a practical demonstration of its capabilities using Natural Language Processing (NLP) features for understanding and analyzing text.
Prerequisites:
Azure AI Language Service: Unleashing Its Power:
Azure AI Language is a cloud-centric solution offering Natural Language Processing (NLP) capabilities for text comprehension and analysis. Using this service we can develop smart applications that manipulate textual content. Here is a complete overview of what the Language service can do with its powerful features:
Named Entity Recognition (NER): It spots entities like names, events, places, and dates from the text with named entity recognition.
Personally identifying (PII) and health (PHI) information detection: Detect and hide sensitive info like phone numbers, email addresses, and IDs in text with PII detection.
Language detection: Figure out the language of a document and get a language code with language detection that works for many languages and variations.
Sentiment Analysis and opinion mining: Learn what people think about our topic with sentiment analysis and opinion mining. These features analyze text to discover positive or negative feelings and link them to specific aspects.
Summarization: Generate document or conversation summaries using summarization, Which extracts key sentences to capture the most crucial information from the original contents
Key phrase extraction: It identifies and lists the main concepts in text with key phrase extraction, a preconfigured feature.
Explore additional features and functionalities within the Language service in this documentation available here. Let’s gain insights into the Summarization feature within the Language Service and integrate it into our compact React application.
In today's fast-paced and information-rich world, the need for efficient content processing has become paramount. Summarization plays a crucial role in addressing this need by distilling lengthy and complex information into concise and digestible forms.
Summarization constitutes one of the capabilities provided by Azure AI Language, a suite of cloud-based machine learning and AI algorithms tailored for crafting intelligent applications centered around written language.
Document summarization employs natural language processing techniques to create a condensed version of a document. The API supports two main approaches to automatic summarization: extractive and abstractive.
Extractive: Selects and extracts sentences directly from the original content that collectively capture the most crucial information.
Abstractive: Creates a summary by generating concise and coherent sentences or words, not limited to extracting sentences from the original document. This approach aims to provide a shortened version of lengthy content.
Let’s create an instance of the Language service to showcase practical summarization and seamlessly integrate it into our React application.
Follow Below Steps to Create an Instance of Language Service:
To Create Instance, log in to your Azure Subscription, go to “Create a resource” and type for language.
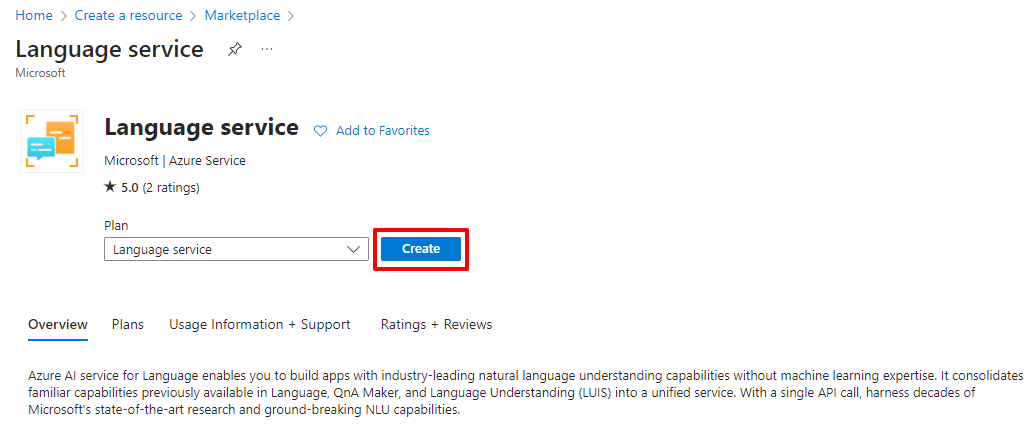
Click on Create and then Continue to Create your resource at bottom.
Fill all the Details with Name of the Instance and Resource. (You can use the free pricing tier (Free F0) to try the service, and upgrade later to a paid tier for production.)
Click on Next Until Review and Create tab.
Verify all the Details and then Click on Create.
After creating the service instance, review the details in the resource group. To utilize the Language service,
Now will obtain Endpoints and an API key by accessing the Language Studio through this link. Login using the Azure Subscription in which you created the instance.
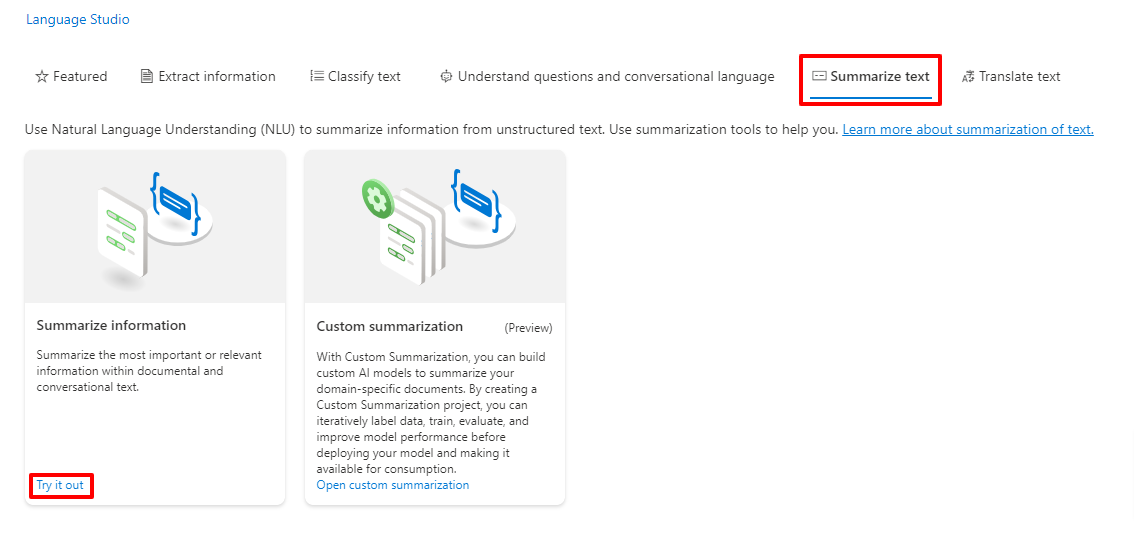
Navigate to the Summarization text tab within Language Studio and choose the "Summarize Information" option.
Now you can explore summarization directly in the Playground or seamlessly integrate it into our application using the provided Endpoints and API Key at bottom. Scroll to the bottom to find Language endpoints and Subscription Key. Ensure you have chosen the correct Resource for the Language service.
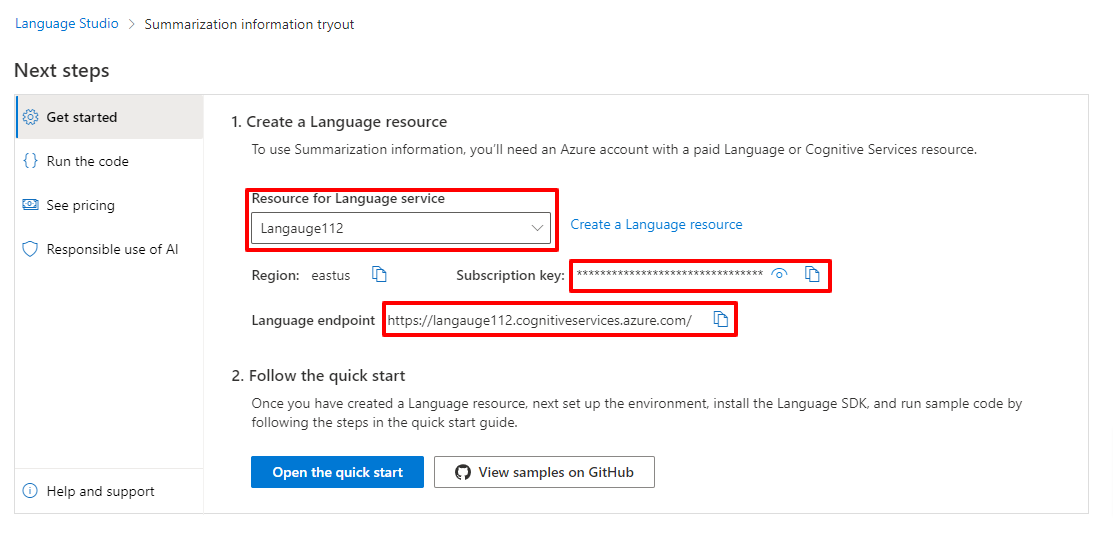
Copy the Subscription Key and Endpoint URL; we will utilize them in our React project.
Setting Up a React Application for Azure Language Service Integration:
The API, along with the obtained Endpoints from the above step, can be employed in various frontend applications. However, for demonstration purposes, we will utilize them in the React app.
Follow below steps to Create the React app and Install all the Packages needs in order to Integrate this:
Note: Ensure that your local development machine has Node version 14 or higher.
Run the "npx create-react-app document-summarize" command to set up the scaffolding for the React app.
Then Install the Client Package Library “npm install --save @azure/ai-language-text@1.1.0” in order to work with Azure AI Language.
Now open the Project in the VS Code.
Create a .env file in the root folder.
Store the EndPoint and APIKey in it as shown below.

Navigate to App.js file in the Folder.
Replace the Code with below code.
import React, { useState } from 'react'; const { AzureKeyCredential, TextAnalysisClient } = require("@azure/ai-language-text"); const endpoint = process.env.REACT_APP_ENDPOINT; const apiKey = process.env.REACT_APP_APIKEY; function App() { const [loading, setLoading] = useState(false); // In Order to Generate the Download Link of the File const download = async(filename, text) => { var previousElement = document.getElementById('downloadLink') if(previousElement){ document.body.removeChild(previousElement); } var element = document.createElement('a'); element.setAttribute('id', "downloadLink"); element.setAttribute('href', 'data:text/plain;charset=utf-8,' + encodeURIComponent(text)); element.setAttribute('download', filename); var linkText = document.createTextNode("Download the summarized version of the file"); element.appendChild(linkText); document.body.appendChild(element); } // In Order to Handle the Input element const handleFileChange = async (event) => { setLoading(true) const file = event.target.files[0]; var input = event.target; var reader = new FileReader(); reader.onload = async function () { var text = reader.result; await analyzeAndSummarizeText(file.name,text) setLoading(false) }; reader.readAsText(input.files[0]); }; // Analyze and Summarize the Text const analyzeAndSummarizeText = async (inputFileName, originalText) => { const client = new TextAnalysisClient(endpoint, new AzureKeyCredential(apiKey)); const actions = [ { kind: "ExtractiveSummarization", maxSentenceCount: 2, }, ]; const analyzeBatch = await client.beginAnalyzeBatch(actions, [originalText], "en"); analyzeBatch.onProgress(() => { console.log( `Last time the operation was updated was on: ${analyzeBatch.getOperationState().modifiedOn}` ); }); const results = await analyzeBatch.pollUntilDone(); for await (const actionResult of results) { if (actionResult.kind !== "ExtractiveSummarization") { throw new Error(`Expected extractive summarization results but got: ${actionResult.kind}`); } if (actionResult.error) { const { code, message } = actionResult.error; throw new Error(`Unexpected error (${code}): ${message}`); } for (const result of actionResult.results) { console.log(`- Document ${result.id}`); if (result.error) { const { code, message } = result.error; throw new Error(`Unexpected error (${code}): ${message}`); } let summarizedTextContent = result.sentences.map((sentence) => sentence.text).join("\n"); await download(inputFileName, summarizedTextContent); } } }; return ( <div id="inputFile"> <input type="file" onChange={handleFileChange} /> { loading && <p>Summarizing the document please wait a while...</p> } </div> ); } export default App;
Save the files, then run "npm start" to initiate the development server on port 3000 and test the solution. Upload the document and wait briefly for the generation of the summarized version. Once ready, click the download link to retrieve the summarized version.
Output:
Conclusion:
Throughout this article, we explored the capabilities of Azure AI Language Service, delving into its features and functionality. Specifically, we seamlessly integrated the Document Summarization feature of the Language service into a React application. By doing so, we harnessed the power of Azure AI Language Service to enhance document processing in a practical and user-friendly manner.