Overview:
In this Article, we will explore C# and how to create real life web scrapper
using Scraper API and HtmlAgilityPack.
Requirement:
Recently, we have implemented a Scraper API to get data from different pages and dump into either CSV file OR Database for
wholesale sourcing and ordering processing of the hospitality company based out Richmond, VA, USA.
Introduction:
What is Scraper API?
Scraper API is used to extract data. Its special purpose is to download large amounts of raw data easily and quickly. It is easy to use. We can scrape by sending the URL you would like to scrape to the API along with your API key and the API will return the HTML responses from the URL you want to scrape.Get API Key from Scraper API?
We need to pass the API key with each Scraper API request to authenticate requests. For that, you need to sign up for an account here. After signing up on Scraper API, you will get 5000 free requests for a trial.WEB SCRAPING USING C#
We are going to perform scraping with HTML parsing. We are going to extract data from https://coinmarketcap.com.
This website holds the information of cryptocurrencies, like name, current
price, the percentage change in the last 24hrs, 7 days, market capital,
etc.
Step-1: Create Project
First, create a project, here we are choosing Console App (.NET Core). You can choose the project template based on your requirement. Right now, our focus is web scraping so, skipped project creation steps.Step-2: Install NuGet Packages
We require to install the following NuGet packages:- ScraperAPI: This is the official C# SDK for the Scraper Api.
- HtmlAgilityPack: It is a .NET code library that allows you to parse "out of the web" HTML files.
Open Package Manager Console and run the below command one by one,
Install-Package ScraperApi Install-Package HtmlAgilityPack
Step-3: GetDataFromWebPage() method
In this example, we are going to use the HttpClient and ScraperApiClient.
1 2 3 4 5 6 7 8 9 10 11 |
static async Task GetDataFromWebPage() { string apiKey = "cb4b88b493a5d003efadb120698c1f14"; HttpClient scraperApiHttpClient = ScraperApiClient.GetProxyHttpClient(apiKey); scraperApiHttpClient.BaseAddress = new Uri("https://coinmarketcap.com"); var response = await scraperApiHttpClient.GetAsync("/"); if (response.StatusCode == HttpStatusCode.OK) { var htmlData = await response.Content.ReadAsStringAsync(); ParseHtml(htmlData); } } |
Replace your Scraper API key with “apiKey” variable.
GetProxyHttpClient() is used to create a HTTP client with the
scraperapi.com.
GetAsync() will fetch the data from the website and store in local variable.
proxy.
Step-4: ParseHtml() method
Once get html data from Webpage, parsing it using the HTMLdocument method. It comes from HtmlAgilityPack.
Next step, load html data and get the ‘tbody’ html tag from it. The tbody
tag contains the rows of Cryptocurrency data.
To get more data, use selectSignleNode method. It will return the first
HtmlNode that matches the XPath query, it will return a null reference if
the matching node is not found. SelectNodes is a collection of Html Nodes.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
static void ParseHtml(string htmlData) { var coinData = new Dictionary < string, string > (); HtmlDocument htmlDoc = new HtmlDocument(); htmlDoc.LoadHtml(htmlData); var theHTML = htmlDoc.DocumentNode.SelectSingleNode("html//body"); var cmcTableBody = theHTML.SelectSingleNode("//tbody"); var cmcTableRows = cmcTableBody.SelectNodes("tr"); if (cmcTableRows != null) { foreach(HtmlNode row in cmcTableRows) { var cmcTableColumns = row.SelectNodes("td"); string name = cmcTableColumns[2].InnerText; string price = cmcTableColumns[3].InnerText; coinData.Add(name, price); } } WriteDataToCSV(coinData); } |
Step-5: WriteDataToCSV() method
In this example, we have taken the currency name and its price from the scraped data, and store in CSV file.
1 2 3 4 5 6 7 8 9 |
static void WriteDataToCSV(Dictionary < string, string > cryptoCurrencyData) { var csvBuilder = new StringBuilder(); csvBuilder.AppendLine("Name,Price"); foreach(var item in cryptoCurrencyData) { csvBuilder.AppendLine(string.Format("{0},\"{1}\"", item.Key, item.Value)); } File.WriteAllText("C:\\Kishan\\Webscraping.csv", csvBuilder.ToString()); } |
Step-6: Main() method
Replace content of Main method with below code:
1 2 3 |
static async Task Main(string[] args) { await GetDataFromWebPage(); } |
Output
We can see CSV file as output that contains two columns, 1) Currency Name and 2) Price. We can get required column and data based on our need.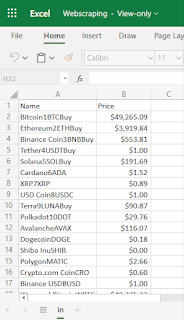
Conclusion
In this blog, with the help of ScraperAPI and HtmlAgility Nuget Packages, we can scrap the data from site, filter the require data and dump into CSV file.
If you have any questions you can reach out our
SharePoint Consulting
team
here.
















